
GPU Communication
1. NVLink
NVLink 是 NVIDIA 开发的一种高速互连技术,旨在实现 GPU 之间以及 GPU 与 CPU 之间的高带宽、低延迟通信。它主要用于加速 AI、HPC 和数据分析等场景中的数据传输。
1.1. CPU 连接
NVLink 不但可以实现 GPU 之间以及 GPU 和 CPU 之间的互联,还可以实现 CPU 之间的互联。从这一点来看,NVLink 的野心着实不小。
我们知道,Intel 的 CPU 间互联总线是 QPI,20 位宽的 QPI 连接带宽也只有 25.6GB/s,在 NVLink 面前同样差距巨大。可想而知,如果全部采用 NVLink 总线互联,会对系统数据交换通道的带宽有多大提升
1.2. NVLink 的关键特性
高带宽:NVLink 提供的带宽远超传统 PCIe,总带宽可达数百 GB/s。最新的 NVLink 4.0 提供了高达 1.8 TB/s 的总带宽。
低延迟:NVLink 具备直接的点对点通信能力,避免了数据绕行 CPU 的延迟。提供了内存一致性模型,确保数据在不同 GPU 之间保持一致。
GPU Direct RDMA(后面重点讲述):支持直接的 GPU 到 GPU 访问,无需通过主机内存,大幅提升性能。2013 年,GPUDirect 增加了 RDMA 支持,使得第三方 PCI Express 设备可以 bypass CPU host memory 直接访问 GPU。
多 GPU 拓扑支持:NVLink 支持多 GPU 拓扑,例如 Fully Connected、Hybrid Cube Mesh 等。NVIDIA 的 NVSwitch 提供了 GPU 间的全互联能力,实现大规模 GPU 集群通信。
1.3. NVLink 的发展历程
• NVLink 1.0 (2016):首发于 Pascal GPU(如 P100),提供 80 GB/s 的带宽。
• NVLink 2.0 (2017):在 Volta 架构中引入,带宽提升至 300 GB/s。
• NVLink 3.0 (2020):用于 Ampere 架构(如 A100),带宽达到 600 GB/s。
• NVLink 4.0 (2022):在 Hopper 架构(如 H100)中推出,总带宽达到 900 GB/s。
• NVLink 5.0 (未来):预计在 Blackwell 架构中进一步提升带宽和效率。
1.4. NVLink 与 AMD 的对比
在高性能计算中,AMD 提供了类似的互连技术,称为 Infinity Fabric:
• Infinity Fabric 在 AMD Instinct GPU 和 EPYC CPU 之间提供高带宽、低延迟的互连。
• AMD 的 Infinity Fabric 3.0 也支持多 GPU 的点对点通信,带宽高达 800 GB/s。
• 相比 NVLink,Infinity Fabric 在异构计算和 CPU-GPU 结合场景中有更好的优化。
2. NVLink 实现(拓补结构)
NVLink 的具体技术实现涉及物理层、数据链路层、传输层等多个层次。它采用了一系列硬件和协议优化,以提供高带宽、低延迟的 GPU 互连。下面详细介绍其关键实现方式。
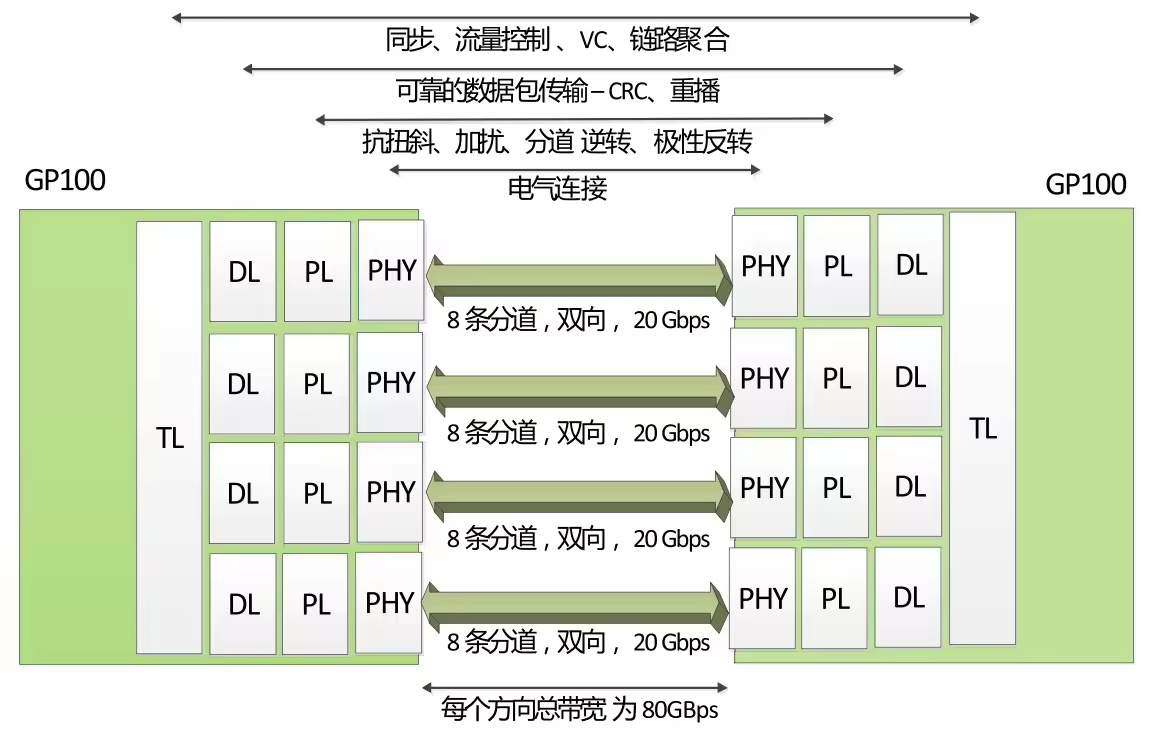 (图中分别是 PHY/PL/DL/TL 层)
(图中分别是 PHY/PL/DL/TL 层)
P100 搭载的 NVLink 1.0,每个 P100 有 4 个 NVLink 通道,每个拥有 40GB/s的双向带宽,每个 P100 可以最大达到 160GB/s带宽。
V100 搭载的 NVLink 2.0,每个 V100 增加了 50%的 NVLink 通道达到 6 个,信号速度提升 28%使得每个通道达到 50G 的双向带宽,因而每个 V100 可以最大达到 300GB/s的带宽。
下图是 HGX-1/DGX-1 使用的 8 个 V100 的混合立方网格拓扑结构,我们看到虽然 V100 有 6 个 NVlink 通道,但是实际上因为无法做到全连接,2 个 GPU 间最多只能有 2 个 NVLink 通道 100G/s的双向带宽。而 GPU 与 CPU 间通信仍然使用 PCIe 总线。CPU 间通信使用 QPI 总线。这个拓扑虽然有一定局限性,但依然大幅提升了同一 CPU Node 和跨 CPU Node 的 GPU 间通信带宽。
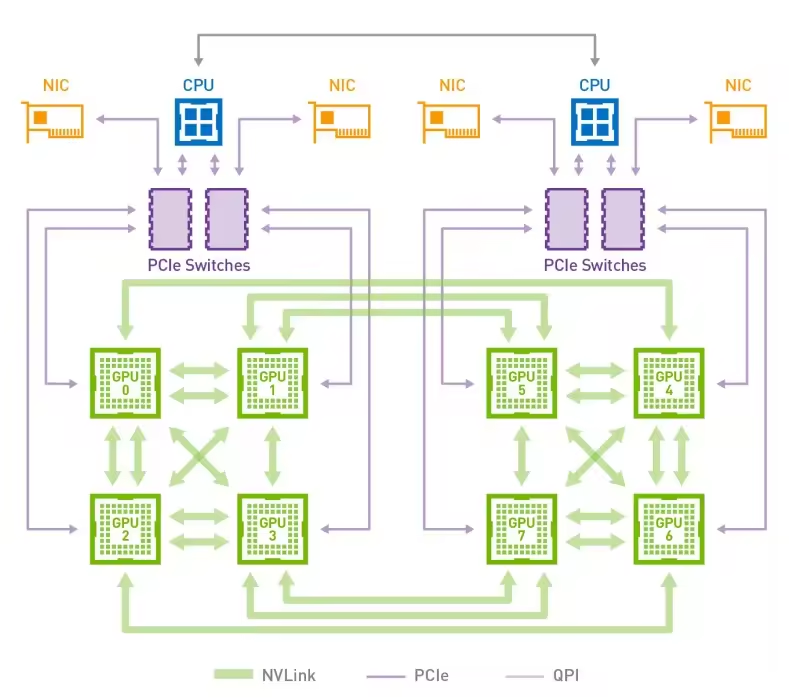
为了解决混合立方网格拓扑结构的问题,NVIDIA 在 GTC 2018 上发布了 NVSwitch。(后文)
2.1. NVLink 物理层 (Physical Layer)
差分信号传输:NVLink 使用高速差分信号进行数据传输,类似于 PCIe,但拥有更高的带宽。
带宽与速率:
- NVLink 3.0 使用 50 Gbps 的 PAM4(4-level Pulse Amplitude Modulation)信号传输,每对通道可以提供更高的带宽。
- NVLink 4.0 使用更先进的信号技术,每个 NVLink 通道提供高达 100 Gbps 的速率。
通道设计:每个 NVLink 通道由 8、16 或 32 条通道组成,每条通道提供双向通信能力。通过多条 NVLink 通道组合,提供数百 GB/s 的带宽。
2.2. 数据链路层 (Data Link Layer)
链路管理:NVLink 使用可靠的链路层协议进行数据包传输,包括错误检测和纠错功能。
ECC (Error Correction Code):NVLink 采用前向纠错编码(FEC)技术,通过冗余位检测和纠正错误。提供高可靠性,即便在高带宽下也能确保数据完整性。
流控与拥塞管理:实现了端到端的流量控制,防止数据丢失和死锁。动态调整数据传输速率,确保通信效率。
2.3. 传输层 (Transport Layer)
消息类型与分包:NVLink 将大数据包拆分成固定大小的小数据包(通常为 128 字节),以实现高效的网络传输。支持多种消息类型,包括内存请求、写入、读取等。
GPU Direct Memory Access (GPU Direct):允许 GPU 直接访问另一台 GPU 的显存,无需经过 CPU。GPU Direct RDMA 提供了跨节点的 GPU 间直接通信。
内存一致性:NVLink 支持强内存一致性模型。使用 Cache Coherent Interconnect 技术,实现 GPU 之间的共享内存视图。
2.4. NVSwitch
类似于 PCIe 使用 PCIe Switch 用于拓扑的扩展,NVIDIA 使用 NVSwitch 实现了 NVLink 的全连接。NVSwitch 作为首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别以 300 GB/s 的惊人速度进行同时通信。这 16 个全互联的 GPU (32G 显存 V100)还可作为单个大型加速器,拥有 0.5 TB 统一显存空间和 2 PetaFLOPS 计算性能。
关于 NVSwitch 的相关技术细节可以参考 NVIDIA 官方技术文档。应该说这一技术的引入,使得 GPU 间通信的带宽又大大上了一个台阶。
在多 GPU 互连场景中,NVIDIA 提供了 NVSwitch 作为互连芯片。NVSwitch 可以支持多达 16 张 GPU 的全互联,提供高达数 TB/s 的总带宽。
它的主要功能包括:
- 数据包路由:根据地址将数据包路由到目标 GPU。
- 拥塞控制:监控网络流量,动态分配带宽。
- 内存一致性管理:确保所有 GPU 的数据视图一致。
2.5. NVLink 的典型拓扑结构
Direct GPU-GPU Topology:用于 2-4 GPU 直接互联的场景。
Hybrid Cube Mesh (HCM):在 8-GPU 系统中采用立方体网格拓扑,每个 GPU 直接连接到多个邻居 GPU。
Fully Connected NVSwitch Topology:在大型数据中心中,通过 NVSwitch 连接多达 16 或 32 张 GPU,实现高带宽全互联。
2.6. NVLink 的优化技术
• P2P(Peer-to-Peer)传输:GPU 之间可以直接通信,无需经过 CPU。2011 年,GPUDirect 增加了相同 PCI Express root complex 下的 GPU 之间的 Peer to Peer (P2P) Direct Access 和 Direct Transfers 的支持。
GPU Direct Peer-to-Peer (P2P) 技术主要用于单机 GPU 间的高速通信,它使得 GPU 可以通过 PCI Express 直接访问目标 GPU 的显存,避免了通过拷贝到 CPU host memory 作为中转,大大降低了数据交换的延迟。
以深度学习应用为例,主流的开源深度学习框架如 TensorFlow、MXNet 都提供了对 GPUDirect P2P 的支持,NVIDIA 开发的 NCCL (NVIDIA Collective Communications Library) 也提供了针对 GPUDirect P2P 的特别优化。
通过使用 GPUDirect P2P 技术可以大大提升深度学习应用单机多卡的扩展性,使得深度学习框架可以获得接近线性的训练性能加速比。
注
受限于 PCI Expresss 总线协议以及拓扑结构的一些限制,无法做到更高的带宽,为了解决这个问题,NVIDIA 提出了 NVLink 总线协议。
• DMA Engine:提供高效的内存拷贝和数据传输。
• 带宽聚合:NVLink 通道支持聚合带宽,使传输任务分布在多个通道上。
2.7. 总结
NVLink 通过高速物理层、多通道数据链路和智能的传输层协议,实现了 GPU 之间的高带宽、低延迟通信。
它的多 GPU 互连拓扑和 NVSwitch 技术为 AI 训练、HPC 仿真等场景提供了强大的数据传输能力。
与 AMD 的 Infinity Fabric 相比,NVLink 更侧重于 GPU-GPU 互连,而 Infinity Fabric 在 CPU-GPU 互连和异构计算场景下表现更优。
3. GPUDirect RDMA
前两篇文章我们介绍的 GPUDirect P2P 和 NVLink 技术可以大大提升 GPU 服务器单机的 GPU 通信性能,当前深度学习模型越来越复杂,计算数据量暴增,对于大规模深度学习训练任务,单机已经无法满足计算要求,多机多卡的分布式训练成为了必要的需求,这个时候多机间的通信成为了分布式训练性能的重要指标。
GPUDirect RDMA (Remote Direct Memory Access) 技术,用于加速多机间 GPU 通信的技术。
在高性能计算(HPC)和人工智能(AI)训练场景中,GPU 通常需要以极高的速度交换数据。NVIDIA 的 GPUDirect RDMA 技术为 GPU 间数据通信提供了一种高效的解决方案。本文将深入剖析 GPUDirect RDMA 的技术原理、实现方式以及典型应用场景。
3.1. 什么是 GPUDirect RDMA?
GPUDirect Remote Direct Memory Access (RDMA) 是 NVIDIA 推出的数据传输技术,允许 GPU 通过 RDMA 网络直接与远程 GPU 或网络设备通信,而无需经过主机 CPU 或系统内存。
在传统的 GPU 通信中,数据往往需要经过以下路径:
- GPU -> 设备内存 (Device Memory)
- PCIe -> 主机内存 (Host Memory)
- CPU 控制数据传输
- 网络接口卡 (NIC) 读取主机内存,再通过网络发送
这种方式带来了额外的延迟和 CPU 开销。
而 GPUDirect RDMA 直接绕过 CPU 和主机内存,让 GPU 数据通过 RDMA 直接传输到远程 GPU 或 NIC,极大地提升了数据传输效率。
3.2. GPUDirect RDMA 的核心技术原理
3.2.1. RDMA 基础
RDMA 技术使设备能够直接访问远程节点的内存,无需 CPU 参与。它主要依赖于以下组件:
Network Interface Card (NIC):支持 RDMA 协议,如 InfiniBand 或 RoCE(RDMA over Converged Ethernet)
Zero-copy:数据直接在 GPU 和远程设备之间传输,不经过中间缓冲区。零复制网络技术使网卡可以直接与应用内存相互传输数据,从而消除了在应用内存与内核之间复制数据的需要。因此,传输延迟会显著减小。
Kernel Bypass:数据路径绕过操作系统内核,减少上下文切换。内核协议栈旁路技术使应用程序无需执行内核内存调用就可向网卡发送命令。在不需要任何内核内存参与的条件下,RDMA 请求从用户空间发送到本地网卡并通过网络发送给远程网卡,这就减少了在处理网络传输流时内核内存空间与用户空间之间环境切换的次数。
RDMA 软件栈:

其中,InfiniBand 是最早实现 RDMA 的网络协议,被广泛应用到高性能计算中。但是 InfiniBand 和传统 TCP/IP网络的差别非常大,需要专用的硬件设备,承担昂贵的价格。相比之下 RoCE 和 iWARP 的硬件成本则要低的多。
所谓 GPUDirect RDMA,就是计算机 1 的 GPU 可以直接访问计算机 2 的 GPU 内存:

简化一些的图:

3.2.2. GPU 和 NIC 直接通信
在 GPUDirect RDMA 中,NIC 通过 PCIe 总线直接访问 GPU 的显存(Device Memory)。主要涉及以下关键机制:
- Memory Pinning:GPU 显存的物理地址需要固定,以便 NIC 直接访问。
- PCIe Peer-to-Peer (P2P):允许 GPU 和 NIC 进行直接的数据传输。
- GPUDirect API:提供了一组接口,使应用程序能够控制 GPU 和网络设备之间的直接数据传输。
3.2.3. 内存注册与映射
为了让 NIC 访问 GPU 显存,需要通过 RDMA 的 Memory Registration 机制将 GPU 的显存地址映射到 NIC 的地址空间。主要包括以下步骤:
- Pinning GPU Memory:固定 GPU 显存,防止数据在传输过程中被移动。
- Address Translation:使用 IOMMU 将 GPU 地址映射到 PCIe 地址空间。
- Remote Memory Access:通过 RDMA Read/Write 操作直接访问远程 GPU 数据。
3.3. GPUDirect RDMA 的优势
低延迟和高带宽
- 消除了 CPU 参与数据传输的额外开销。
- 充分利用 RDMA 网络的高带宽特性。
减少内存拷贝
- 传统方法中,数据需要在 GPU、主机内存和 NIC 之间拷贝多次。
- 使用 GPUDirect RDMA 时,仅需一次数据拷贝即可完成传输。
降低 CPU 负载
- CPU 不再负责数据搬运,仅需处理控制指令。
- 提高整体系统的计算效率。
高效的多 GPU 通信
- 支持 GPU 与 GPU 之间的直接数据交换。
- 适用于分布式深度学习和大规模 HPC 应用。
3.3.1. 典型应用场景
分布式深度学习训练
- 使用 GPUDirect RDMA 实现 GPU 之间的高效梯度交换。
- 在大型 AI 模型训练中大幅减少通信瓶颈。
高性能计算(HPC)
- 在天气预报、分子模拟等场景中,实现节点间的快速数据交换。
数据分析和科学仿真
- 需要大规模数据传输的计算任务,如基因组学、天文学等。
金融服务
- 在高频交易场景中,利用低延迟特性加快交易决策。
3.3.2. 总结
GPUDirect RDMA 技术通过消除 CPU 和主机内存在 GPU 通信中的干预,显著提升了数据传输效率和系统性能。对于需要大规模数据交换的 AI 训练和 HPC 任务,GPUDirect RDMA 已成为不可或缺的加速技术。